Learning to Leap: Humanoid Robot Box Climbing with Reinforcement Learning
Authors: Yahao Fan, Wentao Jiang
Date: November 2024
Abstract
The ability for humanoid robots to perform complex tasks, such as box climbing, while maintaining balance, is a critical challenge in robotics. In this project, we propose Learning to leap a novel approach using reinforcement learning (RL) to enable a humanoid robot, H1, to autonomously climb boxes of varying heights (15-40 cm) while ensuring stability and balance. Our method combines NVIDIA Isaac Gym to simulate realistic environments and generate diverse training data, along with a custom-designed PPO algorithm for policy optimization. The robot's joint is controlled through a PD controller, ensuring smooth motion and efficient adaptation to different box heights. Preliminary results demonstrate that our RL-based system can effectively train the humanoid robot to perform dynamic box climbing while maintaining a high level of balance, opening the door for future applications in agile humanoid robotics.
Overview
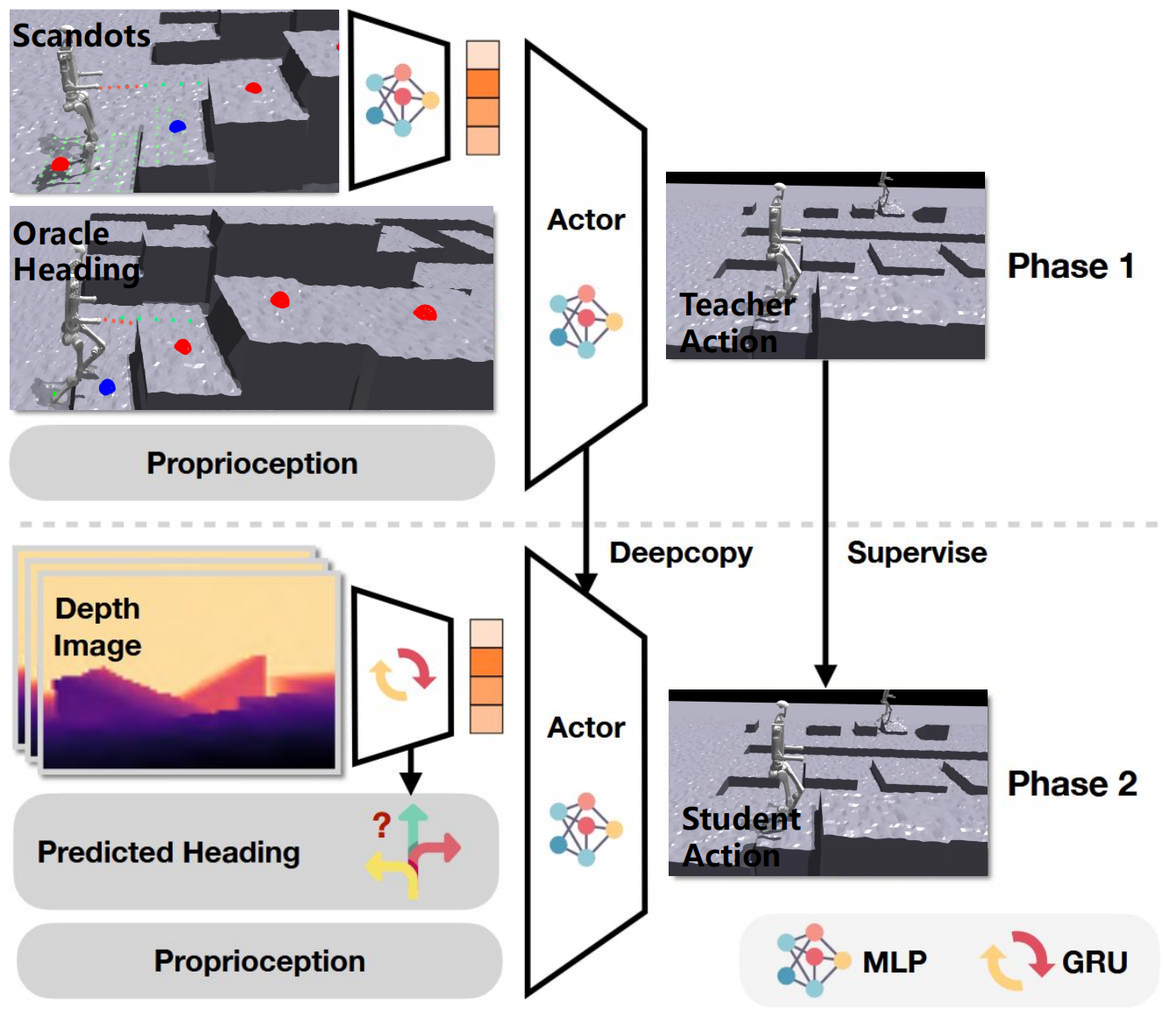
We wish to train a single neural network that goes directly from raw depth and onboard sensing to joint angle commands. To train adaptive motor policies, recent approaches use two-phase student teacher training. Later works introduce regularized online adaptation (ROA) to collapse this into a single phase. To train the vision backbone, a similar teacher-student framework is employed where a teacher trained with privileged scandots information is distilled to a student with access to depth.

Architecture
The proposed system leverages reinforcement learning (RL) to train a humanoid robot, H1, to autonomously climb boxes of varying heights (15-40 cm) while maintaining balance and stability. The system integrates Isaac Gym as the simulation platform, a powerful tool for large-scale parallel RL training, with the Proximal Policy Optimization (PPO) algorithm to optimize the robot's behavior.
Demonstration Videos
As shown, our policy has good generalization and success rate in a variety of complex Parkour terrain, which shows that our policy based on scandot distillation has good generalization ability for terrain.