ReACT : Reactive Bimanual Robot Control
via Action Chunking with Transformers
Authors: KaiYang Ji, Chixuan Zhang
Date: November 2024
Abstract
The field of robotics has seen significant advancements, particularly in robotic manipulation, where the ability to perform complex tasks with precision and adaptability is crucial for integration into various industries. This project introduces ReACT (Reactive Bimanual Robot Control via Action Chunking with Transformers), a novel framework that addresses the challenges of generating effective and context-aware reactions in bimanual operations. ReACT leverages a low-cost teleoperation system based on ALOHA-like robot, allowing an operator to teleoperate one robot arm while training another to autonomously generate complementary reactions. The core of ReACT is the Action Chunking with Transformers (ACT) framework, which encodes human demonstration sequences into temporally cohesive chunks, reducing compounding errors in imitation learning and ensuring smooth and precise motions. The research combines low-cost hardware with advanced learning algorithms, enhancing the robot's ability to perform complex tasks and improving the robustness and adaptability of learned policies. Experiments show that ReACT achieves a high success rate under ideal conditions but is sensitive to environmental disturbances, highlighting the need for further research to enhance robustness. ReACT offers a promising foundation for future developments in robotic manipulation, potentially impacting various industries by enabling more precise, adaptable, and efficient robotic systems.
Overview

The ReACT system in action, illustrating the seamless integration of human-robot interaction and autonomous operation. The dual-arm robot is shown equipped with the ReACT framework, ready to engage in complex tasks. It shows the interaction where the robot, under the guidance of the ReACT algorithm, performs a task alongside a human operator, demonstrating its ability to learn and execute coordinated movements. The Transformer-based training underpins ReACT, enabling the robot to process sensory inputs and generate autonomous actions that are both precise and contextually appropriate.
Architecture
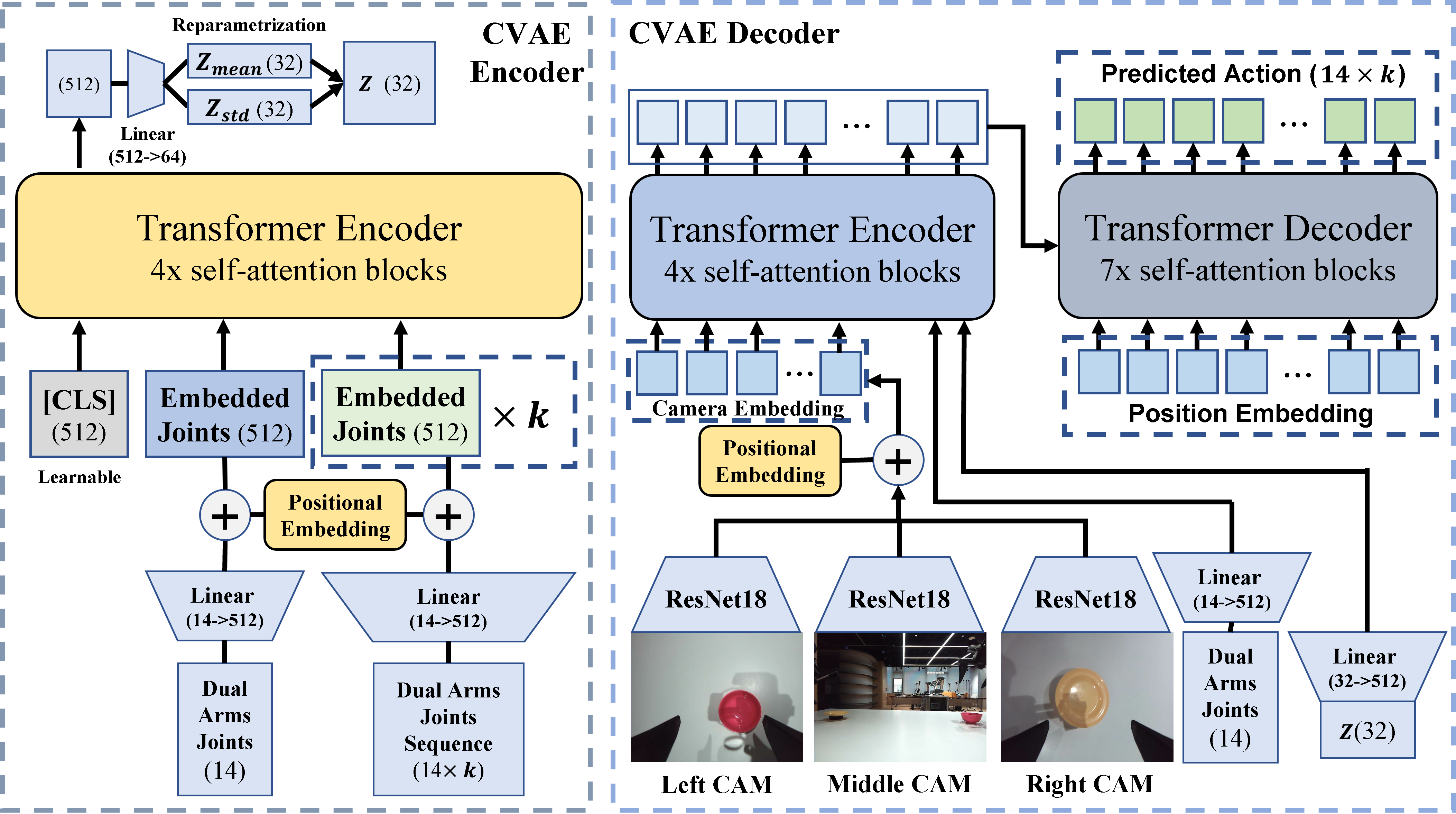
Architecture of ReACT. The diagram illustrates the encoder-decoder structure of ReACT, where the encoder compresses the input action sequences and joint observations into a latent space. This latent space captures the essence of the input data, allowing the model to learn a probabilistic distribution over the actions. The decoder then synthesizes the output actions and images from the latent space, joint positions, and camera embeddings, enabling the system to generate coordinated movements and reactions based on the input observations. The use of transformers in both the encoder and decoder allows ReACT to handle sequential data effectively, capturing long-range dependencies and contextual relationships in the action sequences. During the test time, the encoder will be discarded and the latent space is simply set to the mean of the prior.
Bimanual Teleoperation
Single Arm Reaction
Plate Placing
Generalizability
Generalize to noisy actor operation
Generalize to noisy background
Failure Cases
Human-Robot Collaboration Transfer