A project of the Robotics 2023 class of the School of Information Science and Technology (SIST) of ShanghaiTech University. Course Instructor: Prof. Sören Schwertfeger.
Xiaozhu Lin, Xinlong Li
About This Project
In this project, we trained a Kinova Jaco2 manipulator to learn towel folding skills in only an hour of self-supervised real robot experience, without human supervision, demonstration or simulation. The approach we used relies on fully convolutional networks and the manipulation of visual inputs to exploit learned features, allowing us to create an expressive goal-conditioned pick and place policy that can be trained efficiently with real world robot data only. Folding skills are learned with only a sparse reward function and thus do not require reward function engineering, merely an image of the goal configuration. We demonstrate our method on a set of towel-folding tasks, and show that our approach is able to discover sequential folding strategies, even available for towel with different color, purely from trial-and-error, without the need for demonstrations or simulation.
Methods
In this project, we presented a method for a robot to learn to manipulate deformable objects directly in the real world, without reward function engineering, human supervision, human demonstration, or simulation. Inspired by this work, we used MDP to formulate the folding problem and use Batch RL and HER to train policy offline. In real experiments part, we usedKinova JACO2 and control it by using Kinova API through ROS. RealSense camera is used to capture the image of the towel in data collection and policy evaluation. We utilize a fully-convolutional, deep Q-learning approach that leverages discrete folding distances for sample-efficient real-world learning. Also, we develop a self-supervised learning pipeline for learning towel manipulation via autonomous data collection by the robot in the real world. We formulate the task of folding a piece of towel into a goal configuration as a reinforcement learning (RL) problem with top-down, discrete folding actions. We develop a method that is sample efficient, can learn effectively from sparse rewards and can achieve arbitrary unseen goal configurations given by a single image at test time. We also proposed a novel self-supervised learning approach, in which the robot collects interaction data in the real world without human interaction.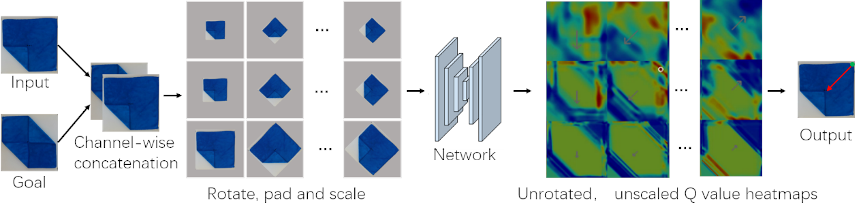
Hardware Description

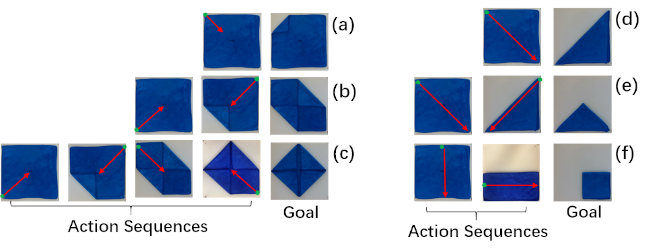

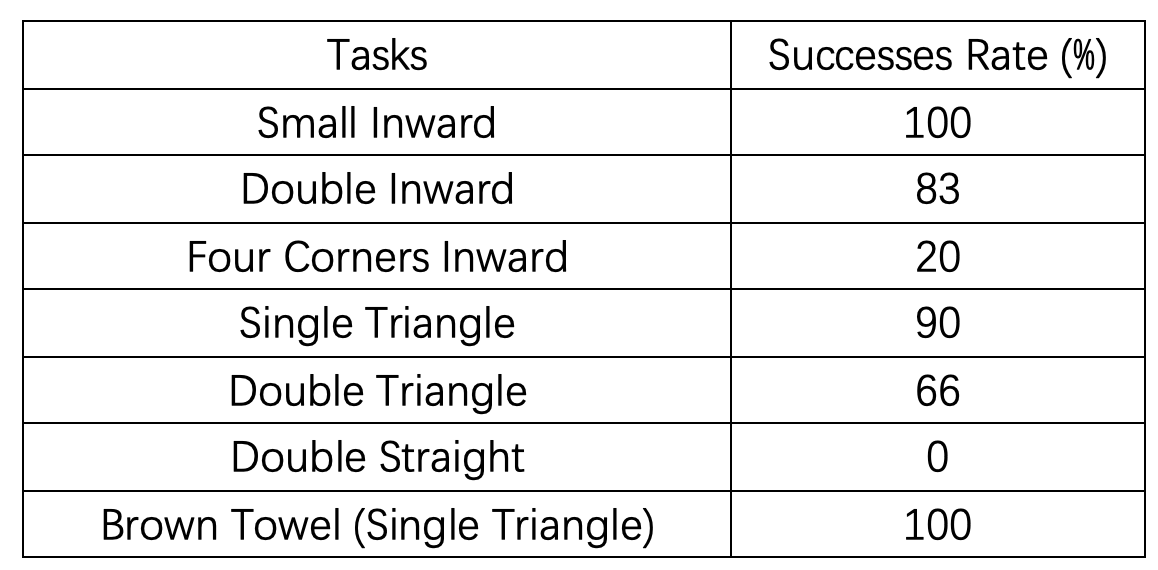
Video