A project of the Robotics 2020 class of the School of Information Science and Technology (SIST) of ShanghaiTech University. Course Instructor: Prof. Sören Schwertfeger.
Delin Feng, Longtian Qiu, Qianjing Shi
Abstract
To date, as development in 5G network and AI or autonomous driving, there has been a surge of interest in 3D point cloud semantic segmentation. Generally speaking, there are three paradigms for point cloud semantic segmentation: projection-based, discretization(voxel) based, and point-based methods. Each of these three methods has its advantages, while, how to solve the lack of small object information in the scene is still a puzzle. In this project, we propose a multi-layer range network for semantic segmention based on U-Net, to solve the problem of missing detailed structure and pose after projection or down-sampling and improve the efficiency and accuracy of the algorithm. Inspired by the voxel structure of Cylinder3D, multilayer processing of the original point cloud data is carried out on the basis of projection-based method, so that it has the advantages similar to voxel. We verify our algorithm via SemanticKITTI dataset and compare results with state of the art methods to evaluate the performance of the algorithm. We also create our own(ShanghaiTech campus) dataset for experiments to verify the efficiency and accuracy of the algorithm.
Introduction
Since deep-learning, machine learning, and computer visions attracts more and more interest, point cloud segmentation (PCS) and 3D point cloud semantic segmentation (PCSS) are popular right now, which is a fundamental and essential capability for real-time intelligent systems like autonomous driving and augmented reality. In large scale 3D point clouds, more semantic information can be provided through efficient semantic segmentation.
People have found that deep learning’s effectiveness for point cloud perception tasks. We are recently witnessing an increasing availability of not interpreted point clouds and 3D models, often shared online using point-based rendering solutions (e.g. PoTree) of mesh-based portals (e.g. Sketchfab). When it comes to point clouds, innovative methods are needed more and more for the analysis and treatment of these data and for their classification, which we finally want to exploit in-depth the informative value of these surveys and representations.
Conventionally, researchers change the point cloud into voxel grids, then process them using 3D volumetric convolutions. It will produce information loss due to low resolutions during voxelization which means many points, if they lie in the same grid, will be merged together. So it is essential to find a high-resolution representation to preserve the fine details in the input data so as to keep it less blur.
We find that projection-based methods include contextual information, but lack 3D structural details. The voxel-based method includes the 3D structure of the point cloud, but requires high resolution and a large memory footprint. Therefore, we want to integrate the advantages of the two methods and construct rich features through multi-dimensional information to achieve a better segmentation effect. Motivated by this, We process point clouds based on spherical coordinate projection to obtain range images, to fuse the features of projection-based and voxel-based methods, we design a multi-layer range image model. Meanwhile, in order to improve the recognition effect of small objects, we propose a U-Net-based convolutional neural network as the backbone of our algorithm. Since there is less open source data for point cloud semantic segmentation, we collect data from the ShanghaiTech campus for experiments. We verify our algorithm via SemanticKITTI.
Method Description
1. Point Cloud Transformation
The projection-based method is widely used in the perception task of the three-dimensional point cloud. The pixel coordinates of the range image can be expressed by using a spherical coordinate system.
In this project, we also considered the discretization of $\theta$ and $\varphi$. Due to the nature of spherical projection, points on similar rays are projected onto the image, they will be in a grid, affected by quantization accuracy, different types of point clouds may be discretized onto the same pixel.
2. Multi-layer Range Images Model
At present, most of the input based on the projection method is a range image, but this has an obvious shortcoming. The point cloud on the same ray will be projected on the same pixel, because only one pixel can be stored Point (usually save the nearest point), the information of the distant point is discarded. This means that when reprojecting (projecting a range image to a three-dimensional point cloud), point clouds that are not involved in the calculation in the distance will be given the category label of the point cloud at the same pixel position.
3. Network Structure
Generally, projection-based methods will use CNN. Due to the use of convolution or pooling layers, the image resolution is reduced.
We have adopted RefineNet as the backbone of the network. RefineNet explicitly utilizes all the information of the downsampling process and uses remote residual connections to achieve high-resolution predictions.
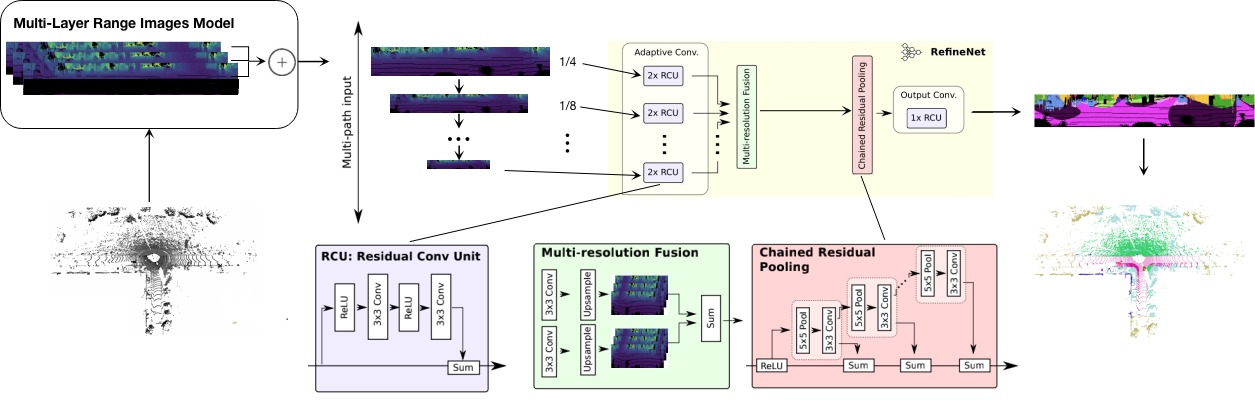
The overall framework of the algorithm MLRSeg
Data Collection


First, Velodyne’s VLP-16 sensor is used and carried by Jackal, a robot car. However the points are too sparse so at last we use Rs-ruby by Robosense.
The pipeline figure shows that how to transform a raw point cloud data into data that can be imported as squeeze input.
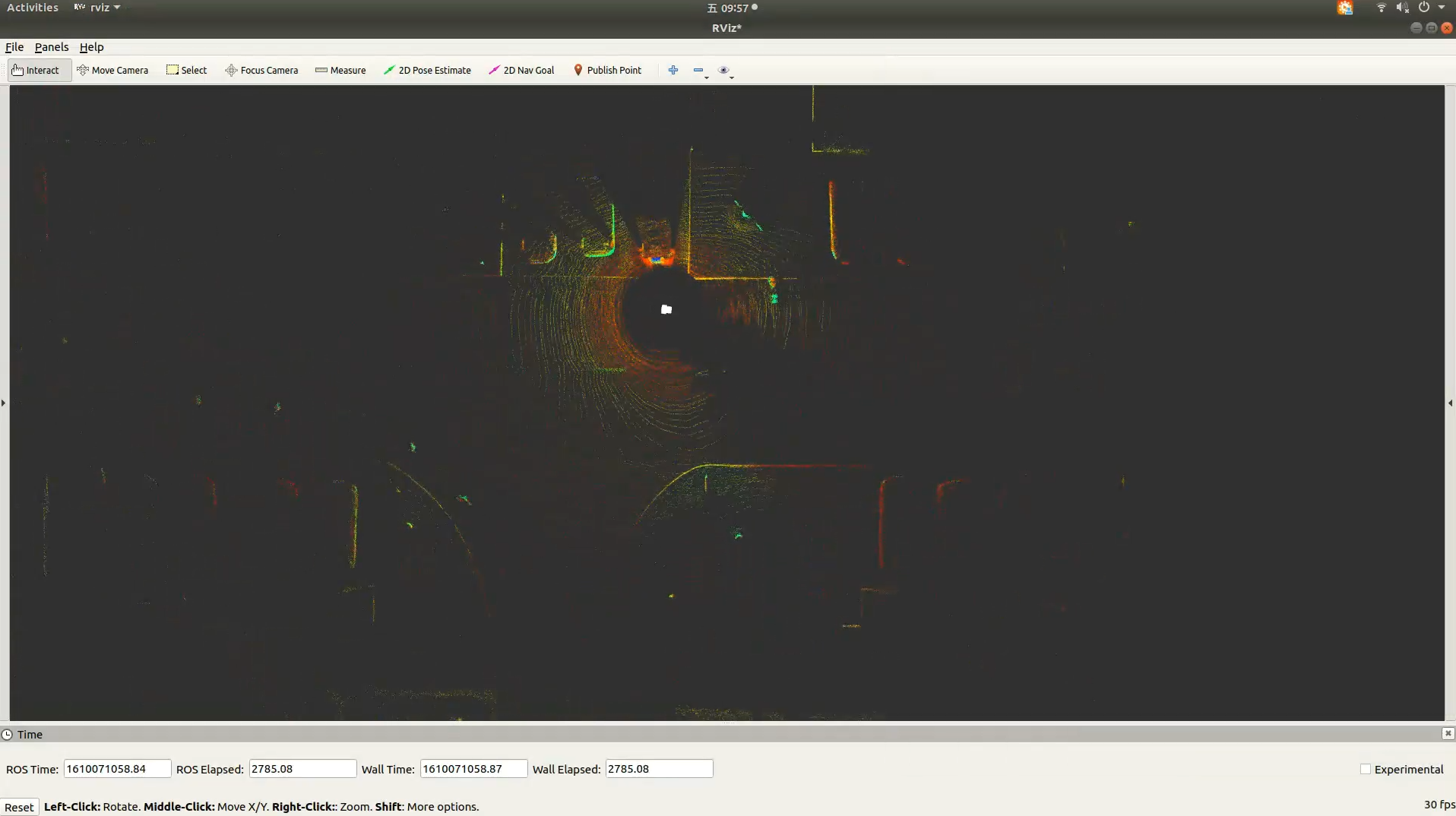
The vis1 and vis2 is the visualization of Robosense's data collecting.
Key contributions
- Design a multi-layer range images model which integrates projection-based and voxel-based frameworks.
- Propose a convolutional neural network for semantic segmentation Based on U-Net.
- The experiments on validation set of SemanticKITTI dataset, our methods shows better performance on some small objects and long-distance objects.
- The point cloud data of ShanghaiTech campus is collected as our own data set, which qualitatively illustrates the feasibility of our algorithm.