A project of the Robotics 2019 class of the School of Information Science and Technology (SIST) of ShanghaiTech University. Course Instructor: Prof. Sören Schwertfeger.
Jiadi Cui, Lei Jin
Introduction
Underwater depth estimation is an open problem for many marine robotics. Currently, there are no available ground truth depths for underwater spherical images. Still, there exists many challenges to capture RGB-D image pairs in the underwater spherical domain, which makes ground truth depth unavailable. In this report, we propose to leverage publicly-available in-airs spherical images for depth estimation in the underwater domain. Specifically, our approach follows a two-stage pipeline. i) Given in-air RGB-D spherical pairs from Stanford 2D-3D-S dataset, we train a style-transfer network to convert in-air images to the underwater domain. ii) Given the generated underwater images and their depth maps, we train a depth estimation network which is specially designed for spherical images. During testing, we can generate depth directly from the input image. Our approach is unsupervised in that only underwater images (i.e., no ground truth underwater depth) are required for the whole training process.

Fig 1. A typical underwater omni-directional image
Methodology
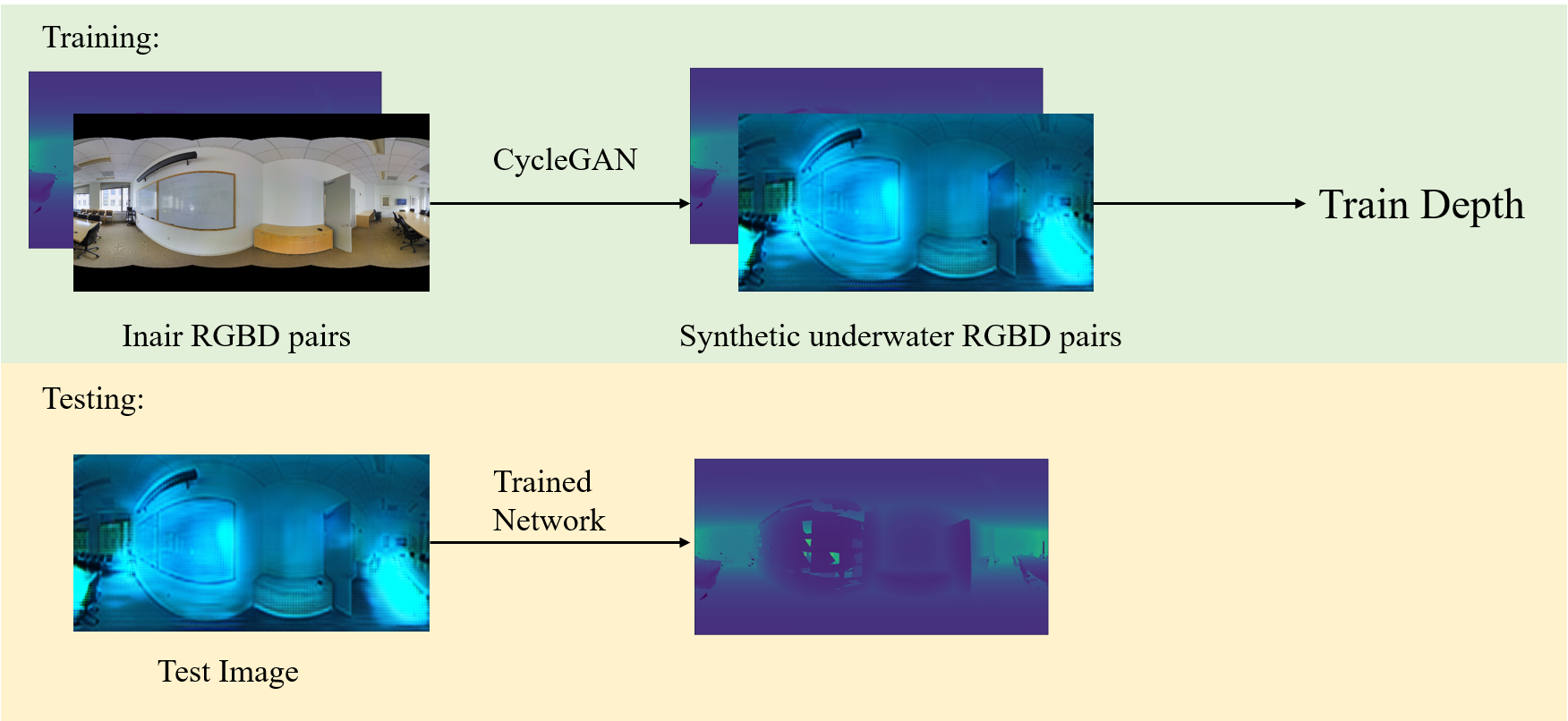
Fig 2. Full pipeline of our approach. We propose to leverage publicly-available RGB-D datasets for style transfer and depth estimation in an unsupervised approach.
Fig 2 demonstrates our two-stage pipeline. i) Given in-air RGB-D spherical pairs from Stanford2D-3D-S dataset, we train CycleGAN to convert in-air images to the underwater domain. ii) Given the generated underwater images and their depth maps, we train a depth estimation network to learn depth. We will introduce the two parts separately in the following context.
Evaluation and Result
Dataset
Stanford 2D-3D-S is one of the standard benchmarks for in-air dataset. The dataset provides omni-directional RGB images and corresponding depth information, which are necessary data for underwater depth estimation tasks. Furthermore, it also provides semantics in 2D and 3D, 3D mesh and surface normal.
Hyper-parameters
We implement our solutions under the PyTorch framework and train our network with the following hyper-parameters settings during pretraining: mini-batch size (8), learning rate (1e-2), momentum (0.9), weight decay (0.0005), and number of epochs (50). We gradually reduce the learning rate by 0.1 every 10 epochs. Finally, we tune the whole network with learning rate (1e-4) for another 20 epochs.
Metrics
We use the following metrics for the comparisons on the datasets mentioned above:
- Root mean square error (RMS)
- Mean relative error (Rel)
- Mean log-10 error (log-10)
- pixel accuracy as the percentage of pixels
represent the ground truths and the depth map predictions, respectively.
Results

Fig 3. Generated images with our CycleGAN. On the left are examples from Domain I, inair. On the right are our generated images. We are able to produce the lightening the color effects from the original underwater dataset.

Fig 4. Generated depth from two datasets. On the left are the input images from the underwater Stanford 2D-3D-S dataset and their predicted depth maps. On the right are images and depth from our underwater datasets.
Since no ground truth depth is available for in the underwater domain, we report the results on the converted Stanford 2D-3D-S dataset. Some quality results of our generated underwater dataset are demonstrated in Fig 3. In Fig 4, we show some results of our depth estimation network. Although we are able to generate realistic images in the underwater domain, and achieve a good results on the underwater Stanford 2D-3D-S dataset, the result of the depth from the underwater images still have room for improvement.
Conclusion
In this project, we aim at unsupervised depth learning for the underwater spherical images. However, this is still specially designed for a certain underwater situation. In the future, we are planning working on a unified approach that can work in all kinds of different underwater situations. Collecting a in-air dataset that looks closer to the underwater images might also further improve our performance.